
11 Representation of Primary Sources
Inhalt
- 11.1 Digital Facsimiles
- 11.2 Combining Transcription with Facsimile
- 11.3 Scope of Transcriptions
- 11.4 Advanced uses of Surface and Zone
- 11.5 Aspects of Layout
- 11.6 Headers, Footers, and Similar Matter
- 11.7 Changes
- 11.8 Other Primary Source Features not Covered in these Guidelines
- 11.9 Module for Transcription of Primary Sources
This chapter defines a module intended for use in the representation of primary sources, such as manuscripts or other written materials. Section 11.1 Digital Facsimiles provides elements for the encoding of digital facsimiles or images of such materials, while the remainder of the chapter discusses ways of encoding detailed transcriptions of such materials. This module may also be useful in the preparation of critical editions, but the module defined here is distinct from that defined in chapter 12 Critical Apparatus, and may be used independently of it. Detailed metadata relating to primary sources of any kind may be recorded using the elements defined by the manuscript description module discussed in chapter 10 Manuscript Description, but again the present module may be used independently if such data is not required.
Although this chapter discusses manuscript materials more frequently than other forms of written text, most of the recommendations presented are equally applicable mutatis mutandis to the encoding of printed matter or indeed any form of written source, including monumental inscriptions. Similarly, where in the following descriptions terms such as ‘scribe’, ‘author’, ‘editor’, ‘annotator’ or ‘corrector’ are used, these may be re-interpreted in terms more appropriate to the medium being transcribed. In printed material, for example, the ‘compositor’ plays a role analogous to the ‘scribe’, while in an authorial manuscript, the author and the scribe are the same person.
11.1 Digital FacsimilesTEI: Digital Facsimiles¶
These Guidelines are mostly concerned with the preparation of digital texts in which pre-existing sources are transcribed or otherwise converted into character form, and marked up in XML. However, it is also very common practice to make a different form of ‘digital text’, which is instead composed of digital images of the original source, typically one per page, or other written surface. We call such a resource a digital facsimile. A digital facsimile may, in the simplest case, just consist of a collection of images, with some metadata to identify them and the source materials portrayed. It may sometimes contain a variety of images of the same source pages, perhaps of different resolutions, or of different kinds. Such a collection may form part of any kind of document, for example a commentary of a codicological or paeleographic nature, where there is a need to align explanatory text with image data. It may also be complemented by a transcribed or encoded version of the original source, which may be linked to the page images. In this section we present elements designed to support these various possibilities and discuss the associated mechanisms provided by these Guidelines.
- att.global.facs groups elements corresponding with all or part of an image, because they contain an
alternative representation of it, typically but not necessarily a transcription of it.
facs (facsimile) points to all or part of an image which corresponds with the content of the element. - att.global.change supplies the change attribute, allowing its member
elements to specify one or more states or revision campaigns with which they are
associated.
change points to one or more change elements documenting a state or revision campaign to which the element bearing this attribute and its children have been assigned by the encoder.
<teiHeader>
<!--...-->
</teiHeader>
<text>
<pb facs="page1.png"/>
<!-- text contained on page 1 is encoded here -->
<pb facs="page2.png"/>
<!-- text contained on page 2 is encoded here -->
</text>
</TEI>
The recommended approach to encoding facsimiles is instead to use the facs attribute in conjunction with the elements facsimile or sourceDoc, and the elements surface, surfaceGrp, and zone, which are also provided by this module. These elements make it possible to accommodate multiple images of each page, as well as to record the position and relative size of elements identified any kind of written surface and to link such elements with digital facsimile images of them. Typical applications include the provision of full text search in ‘digital facsimile editions’, and ways of annotating graphics, for example so as to identify individuals appearing in group portraits and link them to data about the people represented.
- facsimile contains a representation of some written source in the form of a set of images rather than as transcribed or encoded text.
- sourceDoc contains a transcription or other representation of a single source document potentially forming part of a dossier génétique or collection of sources.
- surface defines a written surface as a two-dimensional coordinate space, optionally grouping one or more graphic representations of that space, zones of interest within that space, and transcriptions of the writing within them.
- surfaceGrp defines any kind of useful grouping of written surfaces, for example the recto and verso of a single leaf, which the encoder wishes to treat as a single unit.
- zone defines any two-dimensional area within a surface
element.
points identifies a two dimensional area within the bounding box specified by the other attributes by means of a series of pairs of numbers, each of which gives the x,y coordinates of a point on a line enclosing the area.
- a TEI Header and a text element
- a TEI Header and a facsimile element
- a TEI Header and a sourceDoc element
- a TEI Header, a facsimile element, and a text element
- a TEI Header, one or more sourceDoc or facsimile elements, and a text element
Like the text element, a facsimile element may also contain an optional front or back element, used in the same way as described in sections 4.5 Front Matter and 4.7 Back Matter.
<graphic url="page1.png"/>
<graphic url="page2.png"/>
<graphic url="page3.png"/>
<graphic url="page4.png"/>
</facsimile>
<graphic url="page1.png"/>
<surface>
<graphic url="page2-highRes.png"/>
<graphic url="page2-lowRes.png"/>
</surface>
<graphic url="page3.png"/>
<graphic url="page4.png"/>
</facsimile>
The surface element provides a way of indicating that the two images of page2 represent the same surface within the source material. A surface might be one side of a piece of paper or parchment, an opening in a codex treated as a single surface by the writer, a face of a monument, a billboard, a membrane of a scroll, or indeed any two-dimensional surface, of any size.
<surfaceGrp n="leaf1">
<surface>
<graphic url="page1.png"/>
</surface>
<surface>
<graphic url="page2-highRes.png"/>
<graphic url="page2-lowRes.png"/>
</surface>
</surfaceGrp>
</facsimile>
- att.coordinated elements which can be positioned within a two dimensional
coordinate system.
ulx gives the x coordinate value for the upper left corner of a rectangular space. uly gives the y coordinate value for the upper left corner of a rectangular space. lrx gives the x coordinate value for the lower right corner of a rectangular space. lry gives the y coordinate value for the lower right corner of a rectangular space.
By default, the same coordinate space is used for a surface and for all of its child elements.35 It may be most convenient to derive a coordinate space from a digital image of the surface in question such that each pixel in the image corresponds with a whole number of units (typically 1) in the coordinate space. In other cases it may be more convenient to use units such as millimetres. Neither practice implies any specific mapping between the coordinate system used and the actual dimensions of the physical object represented.
A surface element can contain one or more zone elements, each of which represents a region or bounding box defined in terms of the same coordinate space as that of its parent surface element. A zone may be rectangular or non-rectangular: a rectangular zone is defined by a sequence of four coordinates in the same way as a surface; a non-rectangular zone is defined using the attribute points, which provides a sequence of coordinates, each of which specifies a point on the perimeter of the zone.36
A zone may be used to define any region of interest, such as a detail or illustration, or some part of the surface which is to be aligned with a particular text element, or otherwise distinguished from the rest of the surface. A surface establishes a coordinate system which may be used to address parts or the whole of some digital representation of a written surface. A zone, by contrast, defines any arbitrary area of interest relative to that surface, using the same coordinate system. It might be bigger or smaller than its parent surface, or might overlap its boundaries. The only constraint is that it must be defined using the same coordinate system.
When an image of some kind is supplied within either a zone or a surface, the implication is that the image represents the whole of the zone or surface concerned. In the simple case therefore, we might imagine a surface defining a page, within which there is a graphic representing the whole of that page, and a number of zones defining parts of the page, each with its own graphic, each representing a part of the page. If however one of those graphics actually represents an area larger than the page (for example to include a binding or the surface of a desk on which the page rests), then it will be enclosed by a zone with coordinates larger than those of the parent surface.
 Abbildung 11.1. Badische Landesbibliothek, Manuscript Durlach 1, Fols. 95v-96r
Abbildung 11.1. Badische Landesbibliothek, Manuscript Durlach 1, Fols. 95v-96r <surface
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</surface>
</facsimile>
If desired, the binaryObject element described in 3.9 Graphics and other non-textual components (or any other element from the model.graphicLike class) may be used instead of a graphic element.
<surface
ulx="50"
uly="20"
lrx="400"
lry="280">
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
<zone
ulx="50"
uly="20"
lrx="210"
lry="280">
<!-- left hand page -->
</zone>
<zone
ulx="240"
uly="25"
lrx="400"
lry="280">
<!-- right hand page -->
</zone>
<zone
ulx="90"
uly="40"
lrx="200"
lry="225">
<!--- written part of left hand page -->
</zone>
</surface>
</facsimile>
As this example shows, in addition to acting as a container for graphic elements, zone elements may be used to identify parts of a surface for analytical purposes.
The relationship between zone and surface can be quite complex : for example, it may be appropriate to treat the whole of a two page spread as a single written surface, perhaps because particular written zones span both pages. A zone may contain a nested surface, if for example a page has an additional scrap of paper attached to it. A zone may be of any shape, not simply rectangular. Discussion of these and other cases are provided in section 11.4 Advanced uses of Surface and Zone below.
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
</surface>
</facsimile>
 Abbildung 11.2. Detail of p 49r from Bovelles Géometrie Pratique
Abbildung 11.2. Detail of p 49r from Bovelles Géometrie Pratique<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
<zone
ulx="25"
uly="25"
lrx="180"
lry="60">
<!-- contains the title -->
</zone>
<zone
ulx="28"
uly="75"
lrx="175"
lry="178"/>
<!-- contains the paragraph in italics -->
<zone
ulx="105"
uly="76"
lrx="175"
lry="160"/>
<!-- contains the figure -->
<zone
ulx="45"
uly="125"
lrx="60"
lry="130"/>
<!-- contains the word "pendans" -->
</surface>
</facsimile>
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
<zone
points="4.8,31.0 5.4,30.7 5.5,32.2 5.8,32.8 6.1,33.4 5.5,33.7 5.1,33.3 4.6,32.2"/>
</surface>
</facsimile>
ulx="105"
uly="76"
lrx="175"
lry="160">
<graphic url="Bovelles49r-detail.png"/>
</zone>
11.2 Combining Transcription with FacsimileTEI: Combining Transcription with Facsimile¶
A digitized source document may contain nothing more than page images and a small amount of metadata. It may also contain an encoded transcription of the pages represented, which may either be ‘embedded’ within a sourceDoc element, or supplied in parallel with a facsimile as defined above.
If the transcription is regarded as a text in its own right, organized and structured independently of its physical realization in the document or documents represented by the facsimile, then the recommended practice is to use the text element to contain such a structured representation, and to present it in parallel. The text element is a sibling of the facsimile and sourceDoc elements. This approach is illustrated in section 11.2.1 Parallel Transcription below. Alternatively, if the transcription is intended not to prioritize representation of the final text so much as the process by which the document came to take its present form, or the physical disposition of its component parts, it may be preferable to present it as an embedding transcription, as further described in section 11.2.2 Embedded Transcription below.
11.2.1 Parallel TranscriptionTEI: Parallel Transcription¶
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
xml:id="B49r"
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
</zone>
<zone
ulx="105"
uly="76"
lrx="175"
lry="160">
<graphic url="Bovelles49r-detail.png"/>
</zone>
<zone
xml:id="B49rHead"
ulx="25"
uly="25"
lrx="180"
lry="60"/>
<!-- contains the title -->
<zone
xml:id="B49rPara2"
ulx="28"
uly="75"
lrx="175"
lry="178"/>
<!-- contains the first paragraph in italics -->
<zone
xml:id="B49rFig1"
ulx="105"
uly="76"
lrx="175"
lry="160"/>
<!-- contains the figure -->
<zone
xml:id="B49rW457"
ulx="45"
uly="125"
lrx="60"
lry="130"/>
<!-- contains the word "pendans" -->
</surface>
</facsimile>
<fw>De Geometrie 49</fw>
<head facs="#B49rHead"> DU SON ET ACCORD DES CLOCHES ET <lb/> des alleures des
chevaulx, chariotz & charges, des fontaines:& <lb/> encyclie du monde,
& de la dimension du corps humain.<lb/> Chapitre septiesme</head>
<div n="1">
<p>Le son & accord des cloches pendans en ung mesme <lb/> axe, est faict en
contraires parties.</p>
<p rend="it" facs="#B49rPara2">LEs cloches ont quasi fi<lb/>gures de rondes
pyra<lb/>mides imperfaictes & <lb/> irregulieres: & leur accord se
<lb/> fait par reigle geometrique. Com<lb/>me si les deux cloches C & D
<lb/> sont <w facs="#B49rW457">pendans</w> à ung mesme axe <lb/> ou essieu A B:
je dis que leur ac<lb/>cord se fera en co<ex>n</ex>traires parties<lb/>
co<ex>m</ex>me voyez icy figuré. Car qua<ex>n</ex>d <lb/> lune sera en
hault, laultre declinera embas. Aultrement si elles decli<lb/>nent toutes deux
ensembles en une mesme partie, elles seront discord, <lb/> & sera leur
sonnerie mal plaisante à oyr.<figure facs="#B49rFig1">
<graphic url="Bovelles49r-detail.png"/>
</figure>
</p>
</div>
<surface start="#PB49R">
<graphic url="Bovelles-49r.png"/>
</surface>
</facsimile>
<text>
<body>
<div>
<!-- ... -->
<pb xml:id="PB49R"/>
<fw>De Geometrie 49</fw>
<!-- ... -->
</div>
</body>
</text>
11.2.2 Embedded TranscriptionTEI: Embedded Transcription¶
An embedded transcription is one in which words and other written traces are encoded as subcomponents of elements representing the physical surfaces carrying them rather than independently of them.
- sourceDoc contains a transcription or other representation of a single source document potentially forming part of a dossier génétique or collection of sources.
- surface defines a written surface as a two-dimensional coordinate space, optionally grouping one or more graphic representations of that space, zones of interest within that space, and transcriptions of the writing within them.
- zone defines any two-dimensional area within a surface element.
- line contains the transcription of a topographic line in the source document
- seg (arbitrary segment) represents any segmentation of text below the ‘chunk’ level.
The elements surface, surfaceGrp, and zone were introduced above in section 11.1 Digital Facsimiles When supplied within a sourceDoc element, these elements may contain transcriptions of the written content of a source in addition to or as an alternative to digital images of them. Such transcription may be placed directly within the zone element, or within one or more line elements, for cases where the writing is linear, in the sense that it is composed of discrete tokens organized physically into groups, typically organized in a sequence corresponding with the way they are intended to be read. Depending on the directionality of the writing system used, this might be any combination of top-down and left to right, or vice versa. The element line may be used to hold a complete group of such tokens. Where, however, the lineation is not considered significant, any group of tokens may be indicated using the zone element. The seg element described in section 16.3 Blocks, Segments, and Anchors may also be used to indicate smaller sequences of tokens within zone, or line as appropriate.
Returning to the preceding example, we might transcribe the content of the zone to which we gave the identifier B49rPara2 within a sourceDoc element as follows :
<surface
ulx="0"
uly="0"
lrx="200"
lry="300">
<zone
ulx="0"
uly="0"
lrx="200"
lry="300">
<graphic url="Bovelles-49r.png"/>
</zone>
<!-- ... -->
<zone
ulx="28"
uly="75"
lrx="175"
lry="178">
<line>LEs cloches ont quasi
fi</line>
<line>gures de rondes pyra</line>
<line>mides imperfaictes &
</line>
<line> irregulieres: & leur accord se</line>
<line> fait par reigle geometrique. Com</line>
<line>me si les deux cloches C
& D </line>
<line> sont <zone
ulx="45"
uly="125"
lrx="60"
lry="130">pendans</zone> à ung mesme axe</line>
<line> ou essieu A B: je dis que
leur ac</line>
<line>cord se fera en cõtraires parties</line>
<line> cõme
voyez icy figuré. Car quãd </line>
<line> lune sera en hault, laultre
declinera embas. Aultrement si elles declinent toutes deux ensembles en une
mesme partie, elles seront discord,</line>
<line> & sera leur sonnerie
mal plaisante à oyr.</line>
</zone>
<zone
ulx="105"
uly="76"
lrx="175"
lry="160">
<graphic url="Bovelles49r-detail.png"/>
</zone>
</surface>
</sourceDoc>
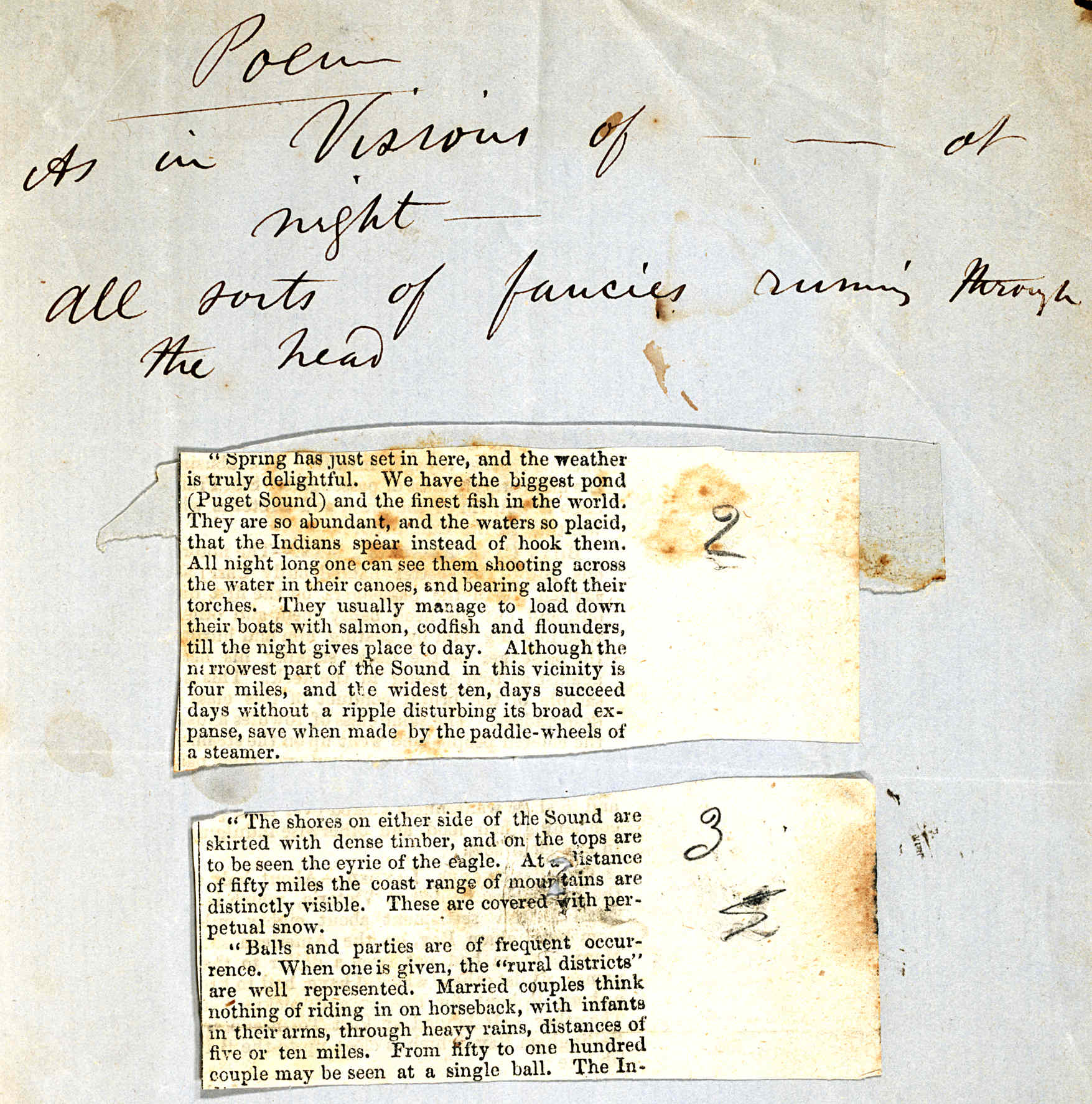 Abbildung 11.3. Single leaf of notes possibly related to the poem eventually titled
Sleepers. From the Walt Whitman Archive (Duke 258).
Abbildung 11.3. Single leaf of notes possibly related to the poem eventually titled
Sleepers. From the Walt Whitman Archive (Duke 258). <zone>
<line>Poem</line>
<line>As in Visions of — at</line>
<line>night —</line>
<line>All sorts of fancies running through</line>
<line>the head</line>
</zone>
<zone>
<surface type="newsprint" attachment="glue" flipping="false">
<zone>Spring has just set in here, and the weather.... a steamer </zone>
<metamark function="sequence">2</metamark>
</surface>
</zone>
<zone>
<surface type="newsprint" attachment="glue" flipping="false">
<zone>"The shores on either side of the Sound are... The In- </zone>
<metamark function="sequence">3</metamark>
</surface>
</zone>
</surface>
The metamark element used in this example is further discussed below (11.3.4.2 Metamarks)
Note that in this example we have not included any graphic element corresponding with the zone or surface elements identified in the transcription. The encoder may choose to complement a transcription with graphic representations of its source at whatever level is considered effective, or not at all. Equally, the encoder may choose to provide only graphics without any transcription, to provide only a structured (non-embedded) transcription, or to provide any combination of the three.
This example also lacks any coordinate information to specify either the size of the two newspaper fragments or whereabouts on the parent surface element they are to be found, other than the reading order implicit in their sequence. Such information could be added if desired by specifying a coordinate system on the outermost surface element, and then indicating values within that system for each of the two fragments, as was discussed above. We discuss this in further detail in section 11.4 Advanced uses of Surface and Zone below.
11.3 Scope of TranscriptionsTEI: Scope of Transcriptions¶
When transcribing a primary source, scholars may wish to record information concerning individual readings of letters, words, or larger units, whether the object is simply a ‘neutral’ transcription or a critical edition. In either case they may also wish to include other editorial material, such as comments on the status or possible origin of particular readings, corrections, or text supplied to fill lacunae.
Such elements may also be used for digital transcriptions in which the object is not to represent a finished text, but rather to represent the creative process, as evidenced by different ‘layers’ or ‘traces’ of writing in one or more documents. Transcriptions of this kind are closely focussed on the physical appearance of specific documents, needing to distinguish the traces of different writing activities on them, such as additions and deletions but also other indications of how the writing is to be read, such as indications of transposition, re-affirmation of writing which has been deleted, and so on. Such distinctions are considered of particular importance when dealing with authorial manuscripts, but are also relevant in the case of historical sources such as charters or other legal documents.
- methods of recording editorial or other alterations to the text, such as expansion of abbreviations, corrections, conjectures, etc. (section 11.3.1 Altered, Corrected, and Erroneous Texts)
- methods of describing important extra-linguistic phenomena in the source: unusual spaces, lines, page and line breaks, changes of manuscript hand, etc. (section 11.3.2 Hands and Responsibility)
- methods of representing complex organizations of surfaces and zones (section 11.4 Advanced uses of Surface and Zone)
- methods of representing aspects of layout such as spacing or lines 11.5 Aspects of Layout
- methods of representing material such as running heads, catch-words, and the like (section 11.6 Headers, Footers, and Similar Matter)
The remainder of this chapter describes a model for encoding such transcriptions, in which elements such as mod, del, etc. are used to mark writing traces and their functions within the document. Each such element can be assigned to one or more editorially-defined modification groups, termed a change, by means of a global change attribute, which references a definition for the modification group concerned, typically provided within the TEI Header creation element; see further 11.7 Changes. The transcription itself may be embedded within the elements surface and zone described in section 11.1 Digital Facsimiles, or provided in parallel within a text element. Within a zone, the transcription may be organized topographically in terms of lines of writing, using the line element, or in terms of further nested zones, or as a combination of the two; see further 11.2.2 Embedded Transcription.
These recommendations are not intended to meet every transcriptional circumstance likely to be faced by any scholar. Rather, they should be regarded as a base which can be elaborated if necessary by different scholars in different disciplines
As a rule, all elements which may be used in the course of a transcription of a single witness may also be used in a critical apparatus, i.e. within the elements proposed in chapter 12 Critical Apparatus. This can generally be achieved by nesting a particular reading containing tagged elements from a particular witness within the rdg element in an app structure.
Just as a critical apparatus may contain transcriptional elements within its record of variant readings in various witnesses, one may record variant readings in an individual witness by use of the apparatus mechanisms app and rdg. This is discussed in section 12.3 Using Apparatus Elements in Transcriptions.
11.3.1 Altered, Corrected, and Erroneous TextsTEI: Altered, Corrected, and Erroneous Texts¶
In the detailed transcription of any source, it may prove necessary to record various types of actual or potential alteration of the text: expansion of abbreviations, correction of the text (either by author, scribe, or later hand, or by previous or current editors or scholars), addition, deletion, or substitution of material, and similar matters. The sections below describe how such phenomena may be encoded using either elements defined in the core module (defined in chapter 3 Elements Available in All TEI Documents) or specialized elements available only when the module described in this chapter is available.
11.3.1.1 Core elements for Transcriptional WorkTEI: Core elements for Transcriptional Work¶
- abbr (abbreviation) contains an abbreviation of any sort.
- add (addition) contains letters, words, or phrases inserted in the text by an author, scribe, annotator, or corrector.
- choice groups a number of alternative encodings for the same point in a text.
- corr (correction) contains the correct form of a passage apparently erroneous in the copy text.
- del (deletion) contains a letter, word, or passage deleted, marked as deleted, or otherwise indicated as superfluous or spurious in the copy text by an author, scribe, annotator, or corrector.
- expan (expansion) contains the expansion of an abbreviation.
- gap (gap) indicates a point where material has been omitted in a transcription, whether for editorial reasons described in the TEI header, as part of sampling practice, or because the material is illegible, invisible, or inaudible.
- sic (Latin for thus or so) contains text reproduced although apparently incorrect or inaccurate.
- att.editLike provides attributes describing the nature of an encoded scholarly intervention or
interpretation of any kind.
evidence indicates the nature of the evidence supporting the reliability or accuracy of the intervention or interpretation. source contains a list of one or more pointers indicating sources supporting the given intervention or interpretation. - att.responsibility provides attributes indicating who is responsible for
something asserted by the markup and the degree of certainty
associated with it.
cert (certainty) signifies the degree of certainty associated with the intervention or interpretation. resp (responsible party) indicates the agency responsible for the intervention or interpretation, for example an editor or transcriber. - att.typed provides attributes which can be used to classify or subclassify elements in any way.
type characterizes the element in some sense, using any convenient classification scheme or typology. subtype provides a sub-categorization of the element, if needed
The following sections describe how the core elements just named may be used in the transcription of primary source materials.
11.3.1.2 Abbreviation and ExpansionTEI: Abbreviation and Expansion¶
The writing of manuscripts by hand lends itself to the use of abbreviation to shorten scribal labour. Commonly occurring letters, groups of letters, words, or even whole phrases, may be represented by significant marks. This phenomenon of manuscript abbreviation is so widespread and so various that no taxonomy of it is here attempted. Instead, methods are shown which allow abbreviations to be encoded using the core elements mentioned above.
A manuscript abbreviation may be viewed in two ways. One may transcribe it as a particular sequence of letters or marks upon the page: thus, a ‘p with a bar through the descender’, a ‘superscript hook’, a ‘macron’. One may also interpret the abbreviation in terms of the letter or letters it is seen as standing for: thus, ‘per’, ‘re’, ‘n’. Both of these views are supported by these Guidelines.
In many cases the glyph found in the manuscript source also exists in the Unicode character set: for example the common Latin brevigraph ⁊, standing for et and often known as the ‘Tironian et’ can be directly represented in any XML document as the Unicode character with code point U+204A (see further Character References and vi.1. Language identification). In cases where it does not, these Guidelines recommend use of the g element provided by the gaiji module described in chapter 5 Representation of Non-standard Characters and Glyphs. This module allows the encoder great flexibility both in processing and in documenting non-standard characters or glyphs, including the ability to provide detailed documentation and images for them.
 Abbildung 11.4. Detail from fol. 126v of Bodleian MS Laud Misc 517
Abbildung 11.4. Detail from fol. 126v of Bodleian MS Laud Misc 517this ladder
<!-- elsewhere -->
<charDecl>
<char xml:id="b-er">
<!-- definition for the er brevigraph -->
</char>
<char xml:id="b-per">
<!-- definition for the per brevigraph -->
</char>
</charDecl>
<abbr>
<g ref="#b-per">per</g>sone
</abbr> ...
<expan>persone</expan> ...
<abbr>eu<g ref="#b-er">er</g>y</abbr>
<expan>euery</expan>
</choice>
- ex (editorial expansion) contains a sequence of letters added by an editor or transcriber when expanding an abbreviation.
- am (abbreviation marker) contains a sequence of letters or signs present in an abbreviation which are omitted or replaced in the expanded form of the abbreviation.
<g ref="#b-er"/>
</am>y</abbr>
<abbr>
<am>
<g ref="#b-per"/>
</am>sone
</abbr> ...
<expan>
<ex>per</ex>sone
</expan> ...
<am>
<g ref="#b-er"/>
</am>
<ex>er</ex>
</choice>y <choice>
<am>
<g ref="#b-per"/>
</am>
<ex>per</ex>
</choice>sone ...
As implied in the preceding discussion, making decisions about which of these various methods of representing abbreviation to use will form an important part of an encoder's practice. As a rule, the abbr and am elements should be preferred where it is wished to signify that the content of the element is an abbreviation, without necessarily indicating what the abbreviation may stand for. The ex and expan elements should be used where it is wished to signify that the content of the element is not present in the source but has been supplied by the transcriber, without necessarily indicating the abbreviation used in the original. The decision as to which course of action is appropriate may vary from abbreviation to abbreviation; there is no requirement that the same system be used throughout a transcription, although doing so will generally simplify processing. The choice is likely to be a matter of editorial policy. If the highest priority is to transcribe the text literatim (letter by letter), while indicating the presence of abbreviations, the choice will be to use abbr or am throughout. If the highest priority is to present a reading transcription, while indicating that some letters or words are not actually present in the original, the choice will be to use ex or expan throughout.
the final d could signify the plural ending (-es, -is, -ys>) but the
singular <hi rend="it">goode</hi> was used with the meaning <q>property</q>,
<q>wealth</q>, at this time (v. examples quoted in OED, sb. Good, C. 7, b,
c, d and 8 spec.)</note>
had good<ex resp="#mp" cert="high">e</ex> I was welbeloued
<resp>Editorial emendations</resp>
<name>Malcom Parkes</name>
</respStmt>
<choice>
<sic>goo<abbr>ɗ</abbr>
</sic>
<expan resp="#mp" cert="high">good<ex>e</ex>
</expan>
</choice> I was
welbeloued
If more than one expansion for the same abbreviation is to be recorded, multiple notes may be supplied. It may also be appropriate to use the markup for critical apparatus; an example is given in section 12.3 Using Apparatus Elements in Transcriptions.
11.3.1.3 Correction and ConjectureTEI: Correction and Conjecture¶
has been modified by James to begin ‘But One must ...’, without the inital capital O having been reduced to lowercase. This non-standard orthography could be recorded thus:One must have lived longer with this system, to appreciate its advantages.
...
<corr>one</corr> must have lived ...
<choice>
<sic>One</sic>
<corr>one</corr>
</choice> must have lived
...
ostendimus quod nutrimentum et
<choice>
<sic>angues</sic>
<corr>augens</corr>
</choice>.
Note that the corr element is used to provide a corrected form which is not present in the source; in the case of a correction made in the source itself, whether scribal, authorial, or by some other hand, the add, del, and subst elements described in 11.3.1.4 Additions and Deletions should be used.
the word create for we create nothing <supplied>we</supplied> develope.
As with expan and abbr, the choice as to whether to record simply that there is an apparent error, or simply that a correction has been applied, or to record both possible readings within a choice element is left to the encoder. The decision is likely to be a matter of editorial policy, which might be applied consistently throughout or decided case by case. If the highest priority is to present an uncorrected transcription while noting perceived errors in the original, the choice will typically be to use only sic throughout. If the highest priority is to present a reading transcription, while indicating that perceived errors in the original have been corrected, the choice will be to use only corr throughout.
Further information may be attached to instances of these elements by the note element and resp and cert attributes. Instances of these elements may also be classified according to any convenient typology using the type attribute.
membres maad, of generacioun And of so parfit wis a <choice xml:id="corr117">
<sic>wight</sic>
<corr>wright</corr>
</choice> ywroght?
<!-- ... -->
<note target="#corr117">This emendation of the Hengwrt copy text, based on a Latin
source and on the reading of three late and usually unauthoritative
manuscripts, was proposed by E. Talbot Donaldson in
<bibl>
<title>Speculum</title> 40 (1965) 626–33.</bibl>
</note>
<!-- somewhere in the header ... --><name xml:id="ETD">E Talbot Donaldson</name>
<!-- ... --> And of so parfit wis a <choice>
<sic>wight</sic>
<corr resp="#ETD" cert="medium">wright</corr>
</choice> ywroght?
<sic>mens</sic>
<corr>iners</corr>
</choice> que nutu dei gesta
sunt ... unde esset uiriliter
<choice xml:id="sic-2">
<corr>uegetata</corr>
<sic>negata</sic>
</choice>
graphically what the scribe should be copying but which does not make sense in
the context.</note>
<sic>mens</sic>
<corr type="graphSubs">iners</corr>
</choice> que nutu dei gesta sunt ... unde
esset uiriliter
<choice>
<corr type="graphSubs">uegetata</corr>
<sic>negata</sic>
</choice>
<sic>mens</sic>
<corr type="graphSubs">iners</corr>
<corr type="reversal">inres</corr>
</choice> que
nutu dei gesta sunt ...
<p>The following codes are used to categorize corrections identified in this
transcription: <list type="gloss">
<label>graphSubs</label>
<item>Substitution of a more familiar word which resembles graphically
what the scribe should be copying but which does not make sense in the
context.</item>
<!-- ... -->
</list>
</p>
</correction>
For a given project, it may well be desirable to limit the possible values for the type or subtype attributes automatically. This is easily done but requires customization of the TEI system using techniques described in 23.2 Personalization and Customization, in particular 23.2.1.4 Modification of Attribute and Attribute Value Lists, which should be consulted for further information on this topic.
parfit wis a <choice>
<sic>wight</sic>
<corr resp="#mp" source="#Gg">wyf</corr>
</choice> ywroght?
Gg. Each witness will be represented either by a
witness element (see 12.1 The Apparatus Entry, Readings, and Witnesses) or more fully by a
msDesc element (see 10 Manuscript Description) : <msIdentifier>
<settlement>Cambridge</settlement>
<repository>University Library</repository>
<idno>Gg.1. 27</idno>
</msIdentifier>
<!-- further description of the manuscript here -->
</msDesc>
<rdg wit="#Hg">wight</rdg>
<rdg wit="#Ln #Ry2 #Ld">wright</rdg>
<rdg wit="#Gg">wyf</rdg>
</app>
<rdg wit="#Hg">wight</rdg>
<rdg wit="#Ln #Ry2 #Ld">
<corr resp="#ETD">wright</corr>
</rdg>
<rdg wit="#Gg">
<corr resp="#mp">wyf</corr>
</rdg>
</app>
Like the resp attribute, the cert attribute may be used with both corr and rdg elements. When used on the rdg element, these attributes indicate confidence in and responsibility for identifying the reading within the sources specified; when used on the corr element they indicate confidence in and responsibility for the use of the reading to correct the base text. If no other source is indicated (either by the source attribute, or by the wit attribute of a parent rdg), the reading supplied within a corr has been provided by the person indicated by the resp attribute.
If it is desired to express certainty of or responsibility for some other aspect of the use of these elements, then the mechanisms discussed in chapter 21 Certainty, Precision, and Responsibility may be found useful. See also 11.3.2.2 Hand, Responsibility, and Certainty Attributes for further discussion of the issues of certainty and responsibility in the context of transcription.
11.3.1.4 Additions and DeletionsTEI: Additions and Deletions¶
- add (addition) contains letters, words, or phrases inserted in the text by an author, scribe, annotator, or corrector.
- addSpan/ (added span of text) marks the beginning of a longer sequence of text added by an author, scribe, annotator or corrector (see also add).
- del (deletion) contains a letter, word, or passage deleted, marked as deleted, or otherwise indicated as superfluous or spurious in the copy text by an author, scribe, annotator, or corrector.
- delSpan/ (deleted span of text) marks the beginning of a longer sequence of text deleted, marked as deleted, or otherwise signaled as superfluous or spurious by an author, scribe, annotator, or corrector.
- att.spanning provides attributes for elements which delimit a span of text by pointing mechanisms rather than by enclosing it.
spanTo indicates the end of a span initiated by the element bearing this attribute.
- att.transcriptional provides attributes specific to elements encoding authorial or
scribal intervention in a text when
transcribing manuscript or similar sources.
seq (sequence) assigns a sequence number related to the order in which the encoded features carrying this attribute are believed to have occurred. status indicates the effect of the intervention, for example in the case of a deletion, strikeouts which include too much or too little text, or in the case of an addition, an insertion which duplicates some of the text already present. hand signifies the hand of the agent which made the intervention.
at first sight. Others — and here is one of them — <add hand="#mb">do ever</add>
improve by recognition ....
<handNote xml:id="mb">Max Beerbohm
holograph</handNote>
<handNote xml:id="dhl">D H Lawrence holograph</handNote>
If deletions are classified systematically, the type attribute may be useful to indicate the classification; when they are classified by the manner in which they were effected, or by their appearance, however, this will lead to a certain arbitrariness in deciding whether to use the type or the rend attribute to hold the information. In general, it is recommended that the rend attribute be used for description of the appearance or method of deletion, and that the type attribute be reserved for higher level or more abstract classifications.
 Abbildung 11.5. Draft letter from Robert Graves to Desmond Flower, 17 Dec 1938 (detail).
Abbildung 11.5. Draft letter from Robert Graves to Desmond Flower, 17 Dec 1938 (detail).
RG somewhere: <person xml:id="RG">
<!-- information about Robert Graves here -->
</person>
</listPerson>
dictionary so much as a corpus of precedents <del hand="#RG">in the</del>:
current, obsolete, <add hand="#RG" place="above">cant,</add> cataphretic and
nonce-words are all included.
<add hand="#RG" place="above">for an
abridgement</add>
</del> in explanation...
<subst>
<add>T</add>
<del>t</del>
</subst>he expressed
The add and del elements defined in the core module suffice only for the description of additions and deletions which fit within the structure of the text being transcribed, that is, which each deletion or addition is completely contained by the structural element (paragraph, line, division) within which it occurs. Where this is not the case, for example because an individual addition or deletion involves several distinct structural subdivisions, such as poems or prose items, or otherwise crosses a structural boundary in the text being encoded, special treatment is needed. The addSpan and delSpan elements are provided by this module for that purpose. (For a general discussion of the issue see further 20 Non-hierarchical Structures).
<!-- ... -->
<body>
<div>
<!-- text here -->
</div>
<addSpan n="added gathering" hand="#heol" spanTo="#p025"/>
<div>
<!-- text of first added poem here -->
</div>
<div>
<!-- text of second added poem here -->
</div>
<div>
<!-- text of third added poem here -->
</div>
<div>
<!-- text of fourth added poem here -->
</div>
<anchor xml:id="p025"/>
<div>
<!-- more text here -->
</div>
</body>
<delSpan spanTo="#EPdelEnd" resp="#EP" rend="strikethrough"/>
<l>To where Saint Mary Woolnoth kept the time,</l>
<l>With a dead sound on the final stroke of nine.</l>
<anchor xml:id="EPdelEnd"/>
<l>There I saw one I knew, and stopped him, crying "Stetson!</l>...
<delSpan rend="verticalStrike" spanTo="#delend01"/> Tis moonlight
<del>upon</del>
<add>over</add> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor xml:id="delend01"/>
</l>
The text deleted must be at least partially legible, in order for the encoder to be able to transcribe it. If all of part of it is not legible, the gap element should be used to indicate where text has not been transcribed, because it could not be. The unclear element described in section 11.3.3.1 Damage, Illegibility, and Supplied Text may be used to indicate areas of text which cannot be read with confidence. See further section 11.3.1.7 Text Omitted from or Supplied in the Transcription and section 11.3.3.1 Damage, Illegibility, and Supplied Text.
11.3.1.5 SubstitutionsTEI: Substitutions¶
Substitution of one word or phrase for another is perhaps the most common of all phenomena requiring special treatment in transcription of primary textual sources. It may be simply one word written over the top of another, or deletion of one word and its replacement by another written above it by the same hand on the same occasion; the deletion and replacement may be done by different hands at different times; there may be a long chain of substitutions on the same stretch of text, with uncertainty as to the order of substitution and as to which of many possible readings should be preferred.
- subst (substitution) groups one or more deletions with one or more additions when the combination is to be regarded as a single intervention in the text.
- substJoin (substitution join) identifies a series of possibly fragmented additions, deletions or other revisions on a manuscript that combine to make up a single intervention in the text
<delSpan rend="verticalStrike" spanTo="#delend02"/> Tis moonlight
<subst>
<del>upon</del>
<add>over</add>
</subst> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor xml:id="delend02"/>
</l>
with <subst>
<del seq="1">this</del>
<del seq="2">
<add seq="1">such a</add>
</del>
<add seq="2">a</add>
</subst> system, to appreciate its advantages.
her pinions fann'd
<substJoin target="#change1 #change2"/>
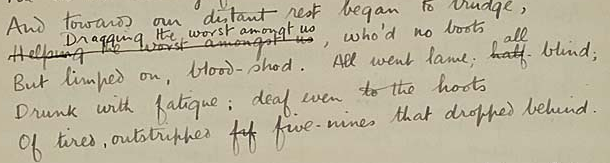 Abbildung 11.6. Detail from Dulce et decorum est autograph manuscript in the
English Faculty Library, Oxford University.
Abbildung 11.6. Detail from Dulce et decorum est autograph manuscript in the
English Faculty Library, Oxford University. <l>
<subst>
<del>Helping the worst amongst us</del>
<add>Dragging the worst amongt
us</add>
</subst>, who'd no boots
</l>
<l>But limped on, blood-shod. All went lame; <subst>
<del status="shortEnd">half-</del>
<add>all</add>
</subst> blind;</l>
<l>Drunk with fatigue ; deaf even to the hoots</l>
<l>Of tired, outstripped <del>fif</del> five-nines that dropped
behind.</l>
- the authorial slip (amongt for amongst) is retained without comment.
- the other two authorial corrections are marked as substitutions, each combining a deletion and an addition.
- the false start fif in the last line is simply marked as a deletion;
<rdg varSeq="1">
<del>this</del>
</rdg>
<rdg varSeq="2">
<del>
<add>such a</add>
</del>
</rdg>
<rdg varSeq="3">
<add>a</add>
</rdg>
</app> system, to appreciate its advantages.
11.3.1.6 Cancellation of Deletions and Other MarkingsTEI: Cancellation of Deletions and Other Markings¶
- restore indicates restoration of text to an earlier state by cancellation of an editorial or authorial marking or instruction.
This element bears the same attributes as the other transcriptional elements. These may be used to supply further information such as the hand in which the restoration is carried out, the type of restoration, and the person responsible for identifying the restoration as such, in the same way as elsewhere.
<del>my</del>
</restore> body
Another feature commonly encountered in manuscripts is the use of circles, lines, or arrows to indicate transposition of material from one point in the text to another. No specific markup for this phenomenon is proposed at this time. Such cases are most simply encoded as additions at the point of insertion and deletions at the point of encirclement or other marking.
11.3.1.7 Text Omitted from or Supplied in the TranscriptionTEI: Text Omitted from or Supplied in the Transcription¶
- gap (gap) indicates a point where material has been omitted in a transcription, whether for editorial
reasons described in the TEI header, as part of sampling practice, or because the material is
illegible, invisible, or inaudible.
reason gives the reason for omission. Sample values include sampling, inaudible, irrelevant, cancelled. hand in the case of text omitted from the transcription because of deliberate deletion by an identifiable hand, signifies the hand which made the deletion. agent In the case of text omitted because of damage, categorizes the cause of the damage, if it can be identified. - surplus marks text present in the source which the editor believes to
be superfluous or redundant.
reason indicates the grounds for believing this text to be superfluous. - supplied signifies text supplied by the transcriber or editor for any
reason, typically because the original cannot be read because of
physical damage or loss to the original.
reason indicates why the text has had to be supplied.
reason="cancelled"
hand="#mb"
quantity="10"
unit="cm"/>—and here is one of
them...
As noted above, the gap element should only be used where text has not been transcribed. If partially legible text has been transcribed, one of the elements damage and unclear should be used instead (these elements are described in section 11.3.3.1 Damage, Illegibility, and Supplied Text); if the text is legible and has been transcribed, but the editor wishes to indicate that they regard it is superfluous or redundant, then the element surplus may be used in preference to the core element sic used to indicate text regarded as erroneous.
- mark this as an erroneous form
- additionally supply a corrected form
- indicate that the erroneous form contains surplus characters which the editor wishes to suppress
tradimento</surplus>
</l>
<l n="5">sì com' l'uccellator prende l'uccello</l>
<gap/>
<l n="43">e lettere dintorno che diriano <surplus reason="interpolated">in questa
guisa</surplus>
</l>
<l n="44">Più v'amo, dëa, che non faccio Deo</l>
<supplied reason="illegible" resp="#msm" source="#Ry2">very humble
Servt</supplied> Sydney Smith
11.3.2 Hands and ResponsibilityTEI: Hands and Responsibility¶
This section discusses in more detail the representation of aspects of responsibility perceived or to be recorded for the writing of a primary source. These include points at which one scribe takes over from another, or at which ink, pen, or other characteristics of the writing change. A discussion of the usage of the hand, resp, and cert attributes is also included.
11.3.2.1 Document HandsTEI: Document Hands¶
For many text-critical purposes it is important to signal the person responsible (the hand) for the writing of a whole document, a stretch of text within a document, or a particular feature within the document. A hand, as the name suggests, need not necessarily be identified with a particular known (or unknown) scribe or author; it may simply indicate a particular combination of writing features recognized within one or more documents. The examples given above of the use of the hand attribute with coding of additions and deletions illustrate this.
- handNote (note on hand) describes a particular style or hand distinguished within a manuscript.
A handNote element, with an identifier given by its xml:id attribute, may appear in either of two places in the TEI Header, depending on which modules are included in a schema. When the transcr module defined by the present chapter is used, the element handNotes is available, within the profileDesc element of the Header, to hold one or more handNote elements. When the msdescription module defined in chapter 10 Manuscript Description is included, the handDesc element described in 10.7.2 Writing, Decoration, and Other Notations also becomes available as part of a structured manuscript description. The encoder may choose to place handNote elements identifying individual hands in either location without affecting their accessibility since the element is always addressed by means of its xml:id attribute. The handDesc element may be more appropriate when a full cataloguing of each manuscript is required; the handNotes element if only a brief characterization of each hand is needed. It is also possible to use the two elements together if, for example, the handDesc element contains a single summary describing all the hands discursively, while the handNotes element gives specific details of each. The choice will depend on individual encoders' priorities.
- handShift/ marks the beginning of a sequence of text written in a new hand, or the beginning of a scribal stint.
- att.handFeatures provides attributes describing aspects of the hand in which a
manuscript is written.
scribe gives a name or other identifier for the scribe believed to be responsible for this hand. script characterizes the particular script or writing style used by this hand, for example secretary, copperplate, Chancery, Italian, etc. scribeRef points to a full description of the scribe concerned, typically supplied by a person element elsewhere in the description. scriptRef points to a full description of the script or writing style used by this hand, typically supplied by a scriptNote element elsewhere in the description. medium describes the tint or type of ink, e.g. brown, or other writing medium, e.g. pencil scope specifies how widely this hand is used in the manuscript.
A single hand may employ different writing styles and inks within a document, or may change character. For example, the writing style might shift from ‘anglicana’ to ‘secretary’, or the ink from blue to brown, or the character of the hand may change. Simple changes of this kind may be indicated by assigning a new value to the appropriate attribute within the handShift element. It is for the encoder to decide whether a change in these properties of the writing style is so marked as to require treatment as a distinct hand.
Where such a change is to be identified, the new attribute indicates the hand applicable to the material following the handShift. The sequence of such handShift elements will often, but not necessarily, correspond with the order in which the material was originally written. Where this is not the case, the facilities described in section 11.7 Changes may be found helpful.
As might be expected, a single hand may also vary renditions within the same writing style, for example medieval scribes often indicate a structural division by emboldening all the words within a line. Such changes should be indicated by use of the rend attribute, in the same manner as underlining, emboldening, font shifts, etc. are represented in transcription of a printed text, rather than by introducing a new handShift element.
<handShift medium="greenish-ink"/>
<l>And if the cattes skynne be slyk <handShift medium="black-ink"/> and
gaye</l>
<handNote xml:id="h1" script="copperplate" medium="brown-ink">Carefully written
with regular descenders</handNote>
<handNote xml:id="h2" script="print" medium="pencil">Unschooled
scrawl</handNote>
</handNotes>
more introduced and Established in this Parish according to the Rules and
Ceremonies of the Church of England and as under a good Consciencious and sober
Curate there would and ought to be <handShift new="#h2" resp="#das"/> and for that
purpose the parishioners pray
When a more precise or nuanced discussion of the writing in a manuscript is required, the handNote and scriptNote elements discussed in 10.7.2 Writing, Decoration, and Other Notations should be used. Either element may serve as the target for a handShift.
11.3.2.2 Hand, Responsibility, and Certainty AttributesTEI: Hand, Responsibility, and Certainty Attributes¶
<choice>
<sic>One</sic>
<corr resp="#FB">one</corr>
</choice> must have lived ...
<!-- elsewhere -->
<respStmt xml:id="FB">
<resp>editorial changes</resp>
<name>Fredson Bowers</name>
</respStmt>
<respStmt xml:id="WJ">
<resp>authorial changes</resp>
<name>William James</name>
</respStmt>
The resp attribute, by contrast, indicates the person responsible for deciding to mark up this part of the text with this particular element. In the case of the add element, for example, the resp attribute will indicate the responsibility for identifying that the addition is indeed an addition, and also (if the hand attribute is supplied) to which hand it should be attributed. In this case, Bowers is credited with identifying the hand as that of William James. In the case of the corr element, the resp attribute indicates who is responsible for supplying the intellectual content of the correction reported in the transcription: here, Bowers' correction of ‘One’ to ‘one’. In the case of a deletion, the resp attribute will similarly indicate who bears responsibility for identifying or categorizing the deletion itself, while other attributes (hand most obviously) attribute responsibility for the deletion itself.
In cases where both the resp and cert attributes are defined for a particular element, the two attributes refer to the same aspect of the markup. The one indicates who is intellectually responsible for some item of information, the other indicates the degree of confidence in the information. Thus, for a correction, the resp attribute signifies the person responsible for supplying the correction, while the cert attribute signifies the degree of editorial confidence felt in that correction. For the expansion of an abbreviation, the resp attribute signifies the person responsible for supplying the expansion and the cert attribute signifies the degree of editorial confidence felt in the expansion.
This close definition of the use of the resp and cert attributes with each element is intended to provide for the most frequent circumstances in which encoders might wish to make unambiguous statements regarding the responsibility for and certainty of aspects of their encoding. The resp and cert attributes, as so defined, give a convenient mechanism for this. However, there will be cases where it is desirable to state responsibility for and certainty concerning other aspects of the encoding. For example, one may wish in the case of an apparent addition to state the responsibility for the use of the add element, rather than the responsibility for identifying the hand of the addition. It may also be that one editor may make an electronic transcription of another editor's printed transcription of a manuscript text—here, one will wish to assign layers of responsibility, so as to allow the reader to determine exactly what in the final transcription was the responsibility of each editor. In these complex cases of divided editorial responsibility for and certainty concerning the content, attributes, and application of a particular element, the more general mechanisms for representing certainty and responsibility described in chapter 21 Certainty, Precision, and Responsibility should be used.
<sic>wight</sic>
<corr resp="#ETD" cert="medium">wright</corr>
</choice>
<corr xml:id="c117">wright</corr>
<sic>wight</sic>
</choice>
<certainty target="#c117" locus="value" degree="0.7"/>
<respons target="#c117" locus="value" resp="#ETD"/>
The above discussion supposes that in each case an encoder is able to specify exactly what it is that one wishes to state responsibility for and certainty about. Situations may arise when an encoder wishes to make a statement concerning certainty or responsibility but is unable or unwilling to specify so precisely the domain of the certainty or responsibility. In these cases, the note element may be used with the type attribute set to ‘cert’ or ‘resp’ and the content of the note giving a prose description of the state of affairs.
11.3.3 Damage and ConjectureTEI: Damage and Conjecture¶
The carrier medium of a primary source may often sustain physical damage which makes parts of it hard or impossible to read. In this section we discuss elements which may be used to represent such situations and give recommendations about how these should be used in conjunction with the other related elements introduced previously in this chapter.
11.3.3.1 Damage, Illegibility, and Supplied TextTEI: Damage, Illegibility, and Supplied Text¶
- damage contains an area of damage to the text witness.
- damageSpan/ (damaged span of text) marks the beginning of a longer sequence of text which is damaged in some way but still legible.
- att.damaged provides attributes describing the nature of any physical damage affecting a reading.
hand In the case of damage (deliberate defacement, inking out, etc.) assignable to a distinct hand, signifies the hand responsible for the damage. agent categorizes the cause of the damage, if it can be identified. degree Signifies the degree of damage according to a convenient scale. The damage tag with the degree attribute should only be used where the text may be read with some confidence; text supplied from other sources should be tagged as supplied. group assigns an arbitrary number to each stretch of damage regarded as forming part of the same physical phenomenon.
- att.dimensions provides attributes for describing the size of physical objects.
extent indicates the size of the object concerned using a project-specific vocabulary combining quantity and units in a single string of words. unit names the unit used for the measurement quantity specifies the length in the units specified - att.ranging provides attributes for describing numerical ranges.
min where the measurement summarizes more than one observation or a range, supplies the minimum value observed. max where the measurement summarizes more than one observation or a range, supplies the maximum value observed. atLeast gives a minimum estimated value for the approximate measurement. atMost gives a maximum estimated value for the approximate measurement.
- att.spanning provides attributes for elements which delimit a span of text by pointing mechanisms rather than by enclosing it.
spanTo indicates the end of a span initiated by the element bearing this attribute.
The following examples all refer to the recto of folio 5 of the unique manuscript of the Elder Edda. Here, the manuscript of Vóluspá has been damaged through irregular rubbing so that letters in various places are obscured and in some cases cannot be read at all.
<!-- ... -->
<pb n="5r"/>
<damageSpan agent="rubbing" extent="whole leaf" spanTo="#damageEnd"/>
</p>
<p> .... </p>
<p> .... <pb n="5v" xml:id="damageEnd"/>
</p>
<l>Moves <damage agent="water" group="1">on: nor all your</damage> Piety nor
Wit</l>
<l>
<damageSpan agent="water" group="1" spanTo="#washOut"/>Shall lure it back to
cancel half a Line,
</l>
<l>Nor all your Tears wash <anchor xml:id="washOut"/> out a Word of it</l>
A more general solution to this problem is provided by the join element discussed in 16.7 Aggregation which may be used to link together arbitrary elements of any kind in the transcription. Here, several phenomena of illegibility and conjecture all result from a single cause: an area of damage to the text caused by rubbing at various points. The damage is not continuous, and affects the text at irregular points. In cases such as this, the join element may be used to indicate which tagged features are part of the same physical phenomenon.
<unclear>aga</unclear>
</damage> yndisniota
<supplied source="#msm">aga</supplied>
</damage> yndisniota
dreki fliugandi naþr frann neþan <gap
reason="illegible"
agent="rubbing"
quantity="4"
unit="letter"/>
<unclear>and the proof of this is</unclear>
<gap/>
<unclear>margin</unclear>
</damage>
11.3.3.2 Use of the <gap>, <del>, <damage>, <unclear>, and <supplied> Elements in CombinationTEI: Use of the gap, del, damage, unclear, and supplied Elements in Combination¶
- where the text has been rendered completely illegible by deletion or damage and no text is supplied by the editor in place of what is lost: place an empty gap element at the point of deletion or damage. Use the reason attribute to state the cause (damage, deletion, etc.) of the loss of text.
- where the text has been rendered completely illegible by deletion or damage and text is supplied by the editor in place of what is lost: surround the text supplied at the point of deletion or damage with the supplied element. Use the reason attribute to state the cause (damage, deletion, etc.) of the loss of text leading to the need to supply the text.
- where the text has been rendered partly illegible by deletion or damage so that the text can be read but without perfect confidence: transcribe the text and surround it with the unclear element. Use the reason attribute to state the cause (damage, deletion, etc.) of the uncertainty in transcription and the cert attribute to indicate the confidence in the transcription.
- where there is deletion or damage but at least some of the text can be read with perfect confidence: transcribe the text and surround it with the del element (for deletion) or the damage element (for damage). Use appropriate attribute values to indicate the cause and type of deletion or damage. Observe that the degree attribute on the damage element permits the encoding to show that a letter, word, or phrase is not perfectly preserved, though it may be read with confidence.
- where there is an area of deletion or damage and parts of the text within that area can be read with perfect confidence, other parts with less confidence, other parts not at all: in transcription, surround the whole area with the del element (for deletion; or the delSpan element where it crosses a structural boundary); or the damage element (for damage). Text within the damaged area which can be read with perfect confidence needs no further tagging. Text within the damaged area which cannot be read with perfect confidence may be surrounded with the unclear element. Places within the damaged area where the text has been rendered completely illegible and no text is supplied by the editor may be marked with the gap element. For each element, one may use appropriate attribute values to indicate the cause and type of deletion or damage and the certainty of the reading.
- if one add element (with identifier ADD1) contains
another (with identifier ADD2), then the addition
ADD1 was first made to the text, and later a second addition
(ADD2) was made within that added text: This is the text <add xml:id="ADD1">with some added <add xml:id="ADD2">(interlinear!)</add> material</add>
as written. - if one del element contains another, and the seq
attribute does not indicate otherwise, it should be assumed that the inner
deletion was made before the enclosing one. In the following example, the word
redundant was deleted before a second deletion
removed the entire passage: <del>This sentence contains some <del>redundant</del> unnecessary
verbiage.</del> - if a del element contains an add element, the normal
interpretation will be that an addition was made within a passage which was
later deleted in its entirety: <del>This sentence was deleted <add>originally</add> from the
text.</del> - if an add element contains a del element, the normal
interpretation will be that a deletion was made from a passage which had
earlier been added: <add>This
sentence was added <del>eventually</del> to the
text.</add>
11.3.4 Marking up the Writing ProcessTEI: Marking up the Writing Process¶
Modifications of various kinds (correction, addition, deletion, etc.) are frequently found within a single document, and may also be inferred when different documents are compared, although it may be an open question as to whether inter-document discrepancies should be regarded in the same way as intra-document alterations. When two witnesses are collated, we may observe that a word present in one is missing from the other: this does not necessarily imply that the word was added to the first witness, nor that it was deleted from the other.
In this section we discuss a number of elements which may be useful when attempting to record traces of the writing process within a document.
11.3.4.1 Generic ModificationTEI: Generic Modification¶
- mod represents any kind of modification identified within a single document.
underline</line> <!-- more lines here -->
<line>wavy underlining finishes
here<anchor xml:id="enduw"/> more words</line>
The distinction between an example such as that above and the simple use of hi to mark the visual salience of the underlining (apart from the use of the spanTo attribute) is that hi does not imply that the visual effect being recorded is understood to represent some kind of modification.
11.3.4.2 MetamarksTEI: Metamarks¶
- metamark contains or describes any kind of graphic or written signal
within a document the function of which is to determine how it
should be read rather than forming part of the actual content of
the document.
function describes the function (for example status, insertion, deletion, transposition) of the mark. target identifies one or more elements to which the function indicated by the metamark applies.
Unlike marginal notes or other additions to the text, metamarks are used by the writer to indicate a deliberate alteration of the writing itself, such as ‘move this passage over there’. An addition or annotation by contrast would typically concern some property of the passage other than its intended location or status within the text flow. A metamark may contain text, or some other graphic which the encoder wishes to represent, or it may simply consist of arrows, dots, lines etc. which the encoder simply describes.
The metamark element carries a function attribute which specifies the function of the metamark, using values such as reorder, flag, delete, insert or used. The passage to which the metamark applies may be indicated in either of two ways: the target attribute may be used to point to the element or elements containing the passage concerned, or the spanTo element may be used to point to a position in the document at which the passage concerned finishes. In the latter case, the metamark itself must be supplied at the position in the document where the passage concerned begins; in the former case it may be supplied at any convenient point. Both attributes should not be supplied.
 Abbildung 11.7. Kundige bok 2, fol 1v.
Abbildung 11.7. Kundige bok 2, fol 1v. <metamark function="flag" target="#zone-1" change="#L2">lege</metamark>
<zone xml:id="zone-1" change="#L1">Ock en schullen de bruwere des hilgen dages
nicht over setten noch uppe den stillen fridach bruwen.</zone>
<addSpan spanTo="#endDel" change="#L2"/>
<zone>Noch nymande over setten, se en sehin denne erst, dat uppe den bonen neyn
stro noch, huw noch flaß ligghe, by pine eyner halven roden, deme bruwere so
wol alse dem bruwheren to murende.</zone>
<anchor xml:id="endDel"/>
The change attribute used here to indicate the sequencing of these various interventions is discussed below, in section 11.7 Changes. The elements addSpan and delSpan are discussed in section 11.3.1.4 Additions and Deletions.
 Abbildung 11.8. From a corrected proof of Miracles (Walt Whitman
Archive)
Abbildung 11.8. From a corrected proof of Miracles (Walt Whitman
Archive)In this example, the whole of what was originally the 14th section of the poem has been marked for deletion, both by horizontal and vertical lines, and by the metamarks resembling the ‘delta’ deletion symbol to left and right of the section. The deletion itself might be encoded by using the normal del or delSpan element, and the metamarks by the metamark element. This is quite a different case from that of the next example, in which the writer does not intend to suppress the content, but only to mark that it has been copied to another manuscript or reused.
 Abbildung 11.9. From "I am that halfgrown angry boy" (MS q 25), David M. Rubenstein Rare
Book & Manuscript Library, Duke University.
Abbildung 11.9. From "I am that halfgrown angry boy" (MS q 25), David M. Rubenstein Rare
Book & Manuscript Library, Duke University. This page contains internal deletions, additions, and retracings but these are semantically quite different from the apparent ‘deletion’ signalled by the larger of the two single vertical lines, which shows that the written material has been transferred or re-used, not deleted.
<metamark function="used" rend="line" target="#X2"/>
<zone xml:id="X2">
<line>I am that halfgrown <add>angry</add> boy, fallen asleep</line>
<line>The tears of foolish passion yet undried</line>
<line>upon my cheeks.</line>
<!-- ... -->
<line>I pass through <add>the</add> travels and <del>fortunes</del> of
<retrace>thirty</retrace>
</line>
<line>years and become old,</line>
<line>Each in its due order comes and goes,</line>
<line>And thus a message for me comes.</line>
<line>The</line>
</zone>
<metamark function="used" target="#X2">Entered - Yes</metamark>
</surface>
In this example, we class as metamarks both the long vertical line and the annotation
‘Entered - yes’.
Both metamarks are assumed to indicate that the whole of the written zone with
identifier X2 is marked as having been used.
11.3.4.3 Fixation and ClarificationTEI: Fixation and Clarification¶
- retrace contains a sequence of writing which has been retraced, for example by over-inking, to clarify or fix it.
 Abbildung 11.10. From autograph ms of Peer Gynt, Collin 2869, 4°,
I.1.1, the Royal Library of Copenhagen
Abbildung 11.10. From autograph ms of Peer Gynt, Collin 2869, 4°,
I.1.1, the Royal Library of Copenhagen Abbildung 11.11. Detail from autograph ms
Brand in The Royal Library, Denmark (KBK Collin 262)
Abbildung 11.11. Detail from autograph ms
Brand in The Royal Library, Denmark (KBK Collin 262) <retrace cause="unclear" change="#stage1">er</retrace>
</retrace> ...</line>
The retrace element is used only for cases where text has been written multiple times. When metamarks and other markup-like strokes have been rewritten multiple times, the redo element described in the next section should be used in preference.
11.3.4.4 Confirmation, Cancellation, and Reinstatement of ModificationsTEI: Confirmation, Cancellation, and Reinstatement of Modifications¶
A writer may indicate that an alteration is itself to be altered: for example, a struck-through passage may be restored via a dotted underlining, or the underlining of a passage may be deleted by a wavy line.
- redo/ indicates one or more cancelled interventions in a
document which have subsequently been
marked as reaffirmed or repeated.
target points to one or more elements representing the interventions which are being reasserted. - undo/ indicates one or more marked-up interventions in a document
which have subsequently been marked for cancellation.
target points to one or more elements representing the interventions which are to be reverted or undone.
The element restore (11.3.1.6 Cancellation of Deletions and Other Markings) is provided for the comparatively simple case where a simple deletion is marked as having been subsequently cancelled. The undo element discussed here is more widely applicable and may be used for any kind of cancellation. It points to the element or elements which are being cancelled. These components need not be contiguous, provided that the cancellation is clearly a single act; each distinct act of cancellation requires a distinct undo element, however. Either of the attributes target or spanTo may be used to indicate the passages concerned.
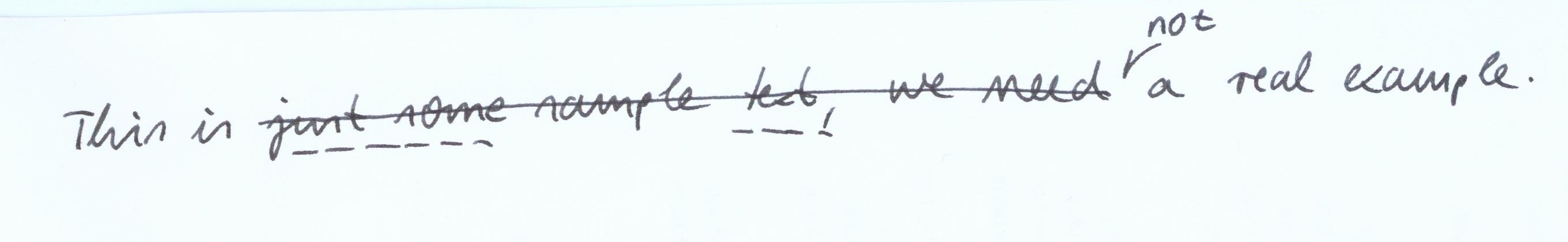 Abbildung 11.12. Imaginary example demonstrating restoring and undoing
Abbildung 11.12. Imaginary example demonstrating restoring and undoing- This is just some sample text, we need a real example.
- This is not a real example.
- This is just some text, not a real example.
<undo spanTo="#Xa" rend="dotted" change="#s3"/>just some <anchor xml:id="Xa"/> sample <undo spanTo="#Xb" rend="dotted" change="#s3"/>text, <anchor xml:id="Xb"/> we need</del>
<add change="#s2">not</add> a real example.</line>
<seg xml:id="X-a">just some</seg> sample <seg xml:id="X-b">text</seg>, we
need</del>
<add change="#s2">not</add> a real example.</line>
<undo target="#X-a #X-b" rend="dotted" change="#s3"/>
11.3.4.5 TranspositionsTEI: Transpositions¶
- listTranspose supplies a list of transpositions, each of which is indicated at some point in a document typically by means of metamarks.
- transpose describes a single textual transposition as an ordered list of at least two pointers specifying the order in which the elements indicated should be re-combined.
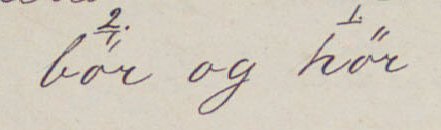 Abbildung 11.13. Extract from autograph Digte
(Poems) NBO Ms. 4º 1110a
Abbildung 11.13. Extract from autograph Digte
(Poems) NBO Ms. 4º 1110a<seg xml:id="ib01">bör</seg>
<metamark
rend="underline"
function="transposition"
target="#ib01"
place="above">2.</metamark> og <seg xml:id="ib02">hör</seg>
<metamark
rend="underline"
function="transposition"
target="#ib02"
place="above">1.</metamark>
</line>
<listTranspose>
<transpose>
<ptr target="#ib02"/>
<ptr target="#ib01"/>
</transpose>
</listTranspose>
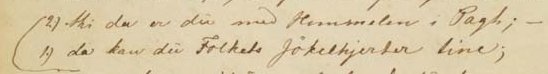 Abbildung 11.14. Detail from autograph ms of Den episke
Brand (KBK Collin 2869)
Abbildung 11.14. Detail from autograph ms of Den episke
Brand (KBK Collin 2869)<metamark function="transposition" place="margin-left">2.)</metamark> thi da er du med Himmelen i Pagt; —
</line>
<line xml:id="ib4">
<metamark function="transposition" place="margin-left">1.)</metamark> da kan du
Folkets Jøkelhjerter tine;
</line>
<listTranspose>
<transpose>
<ptr target="#ib4"/>
<ptr target="#ib3"/>
</transpose>
</listTranspose>
One or more listTranspose elements may be supplied either embedded within the text or in the profileDesc of the header, depending on local preference. Each listTranspose can contain one or more transpose elements, each of which defines a single transposition.
11.3.4.6 Alternative ReadingsTEI: Alternative Readings¶
 Abbildung 11.15. Detail from autograph manuscript of the second version of Lalla
Rookh, Pierpont Morgan MA 310
Abbildung 11.15. Detail from autograph manuscript of the second version of Lalla
Rookh, Pierpont Morgan MA 310<line>Alone <seg xml:id="alt1">before</seg>
<add place="above" xml:id="alt2">beside</add> his native river —</line>
<alt target="#alt1 #alt2" mode="excl" weights="0 1"/>
</zone>
The mode attribute here indicates that the two possible readings indicated by the target attribute are mutually exclusive. The weights attribute indicates the relative importance or preference to be attached to the two readings on a scale running from zero (most improbable) to one (most probable). In this case, we have a very strong preference for the second reading because this is the one that appears in the published version of the poem. The alt element is further discussed in section 16.8 Alternation.
11.3.4.7 Instant CorrectionsTEI: Instant Corrections¶
The use of elements such as del and add necessarily implies that the modifications they indicate were made at some time after the original writing. An exception to this is where a false start or ‘instant’ correction has been identified: the author starts to write, and then immediately corrects what has been written.
The instant attribute defined by this module may be used on any element
which is a member of the att.editLike class to modify
this default assumption. When the value of instant is set to
true, the addition or deletion is considered to belong to the same
change as its parent element, while false means some change later than
that of its parent.
 Abbildung 11.16. Detail fron [I am a curse], one of the drafts for Whitman's
Song of Myself
Abbildung 11.16. Detail fron [I am a curse], one of the drafts for Whitman's
Song of Myself- The letter T is written and then immediately deleted
- The word The is written, deleted, and replaced by the word His
- The added word His is then deleted
- The initial letter i of the words iron necklace is overwritten with a capital I
<del instant="true">T</del>
<mod type="subst">
<del>The</del>
<add place="above">
<del rend="overstrike">His</del>
</add>
</mod>
<mod type="subst">
<del rend="overwritten">i</del>
<add place="superimposed">I</add>
</mod>ron necklace
</line>
11.4 Advanced uses of Surface and ZoneTEI: Advanced uses of Surface and Zone¶
The function of the surface element is both to identify a specific area containing writing and to provide a two dimensional set of coordinates which can be used to position and provide dimensions for sub-parts of it. Furthermore, surfaces may nest within other surfaces, as in the case of ‘patches’ or other written materials attached to the main writing surface. In the general case, the position and dimensions of such nested surfaces will be defined using the same coordinate system as that supplied by the parent surface element. It is also possible, however, that a different coordinate system is required for such a nested surface, perhaps because it requires a more complex granularity. We consider both possibilities.
ulx="0"
uly="0"
lrx="50"
lry="50">
<zone
ulx="1"
uly="1"
lrx="10"
lry="10">
<line>Poem</line>
<line>As in Visions of — at</line>
<line>night —</line>
<line>All sorts of fancies running through</line>
<line>the head</line>
</zone>
<zone
ulx="4"
uly="4"
lrx="20"
lry="20">
<surface type="newsprint" attachment="glue" flipping="false">
<zone>Spring has just set in here, and the weather.... a steamer </zone>
<metamark function="sequence">2</metamark>
</surface>
</zone>
</surface>
ulx="0"
uly="0"
lrx="50"
lry="50">
<zone
ulx="1"
uly="1"
lrx="10"
lry="10">
<line>Poem</line>
<!-- ... -->
<line>the head</line>
</zone>
<zone
ulx="4"
uly="4"
lrx="20"
lry="20">
<surface
ulx="0"
uly="0"
lrx="100"
lry="100">
<zone
ulx="10"
uly="10"
lrx="90"
lry="95"> Spring has just set in here, and the
weather .... a steamer </zone>
</surface>
</zone>
</surface>
All of the examples so far given have involved rectangular zones, for clarity of exposition. As noted above, the points attribute may be used to define non-rectangular zones as a series of points. For example, in the last of the Whitman examples discussed in section 11.3.4.2 Metamarks above, we might wish to record the exact shape of the zone containing the metamark Entered. Since this is not a rectangular zone, we use the points attribute to indicate the points defining a polygon which contains it. The values used are expressed in terms of a coordinate space running from 0 to 229 in the X dimension, and 0 to 160 in the Y dimension.
ulx="0"
uly="0"
lrx="229"
lry="160">
<graphic url="whitman-02.jpg"/>
<zone
xml:id="entered"
points="142,122 155,113 178,122 208,144 198,154 178,139"/>
</surface>
 Abbildung 11.17. Gravestone of Private Moulds
Abbildung 11.17. Gravestone of Private Mouldsxml:id="badge"
ulx="14.54"
uly="16.14"
lrx="0"
lry="0">
<graphic url="stone.jpg"/>
<zone
xml:id="county"
points="4.6,6.3 5.25,5.85 6.2,6.6 8.2,7.4 9.9,6.6 10.9,6.1 11.4,6.7 8.2,8.3 6.2,7.6"/>
</surface>
<surface
ulx="50"
uly="20"
lrx="400"
lry="280">
<!-- ... -->
</surface>
</facsimile>
<surface
ulx="50"
uly="20"
lrx="400"
lry="280">
<zone
ulx="0"
uly="0"
lrx="500"
lry="321">
<graphic
url="http://upload.wikimedia.org/wikipedia/commons/5/50/Handschrift.karlsruhe.blb.jpg"/>
</zone>
</surface>
</facsimile>
11.5 Aspects of LayoutTEI: Aspects of Layout¶
<surfaceGrp type="quire" n="1">
<surfaceGrp type="leaf" n="1">
<surface type="recto" n="1r">
<!-- ... -->
</surface>
<surface type="verso" n="1v">
<!-- ... -->
</surface>
</surfaceGrp>
<surfaceGrp type="leaf" n="2">
<surface type="recto" n="2r">
<!-- ... -->
</surface>
<surface type="verso" n="2v">
<!-- ... -->
</surface>
</surfaceGrp>
<!-- other leaves in first quire -->
</surfaceGrp>
<!-- other quires here -->
</sourceDoc>
 Abbildung 11.18. Opening from autograph ms of Proust's A la recherche du
temps perdu (f 42v-43r)
Abbildung 11.18. Opening from autograph ms of Proust's A la recherche du
temps perdu (f 42v-43r)The coloured lines added to this image indicate a number of zones of writing, colour coded to indicate the order in which they were written (purple, then green, then red). For example, the zone marked in red on the left contains a note referring to the purple zone on the right.
This approach assumes that the transcription will primarily be organized in the same way as the physical layout of the source, using embedded transcription elements. Alternatively, where the a non-embedded transcription has been provided, using the text element, it is still possible to record gathering breaks, page breaks, column breaks, line breaks etc in the source, using the elements described in section 3.10 Reference Systems. Detailed metadata about the physical make-up of a source will usually be summarized by the physDesc component of a msDesc element discussed in 10.7 Physical Description.
11.5.1 SpaceTEI: Space¶
- space indicates the location of a significant space in the copy text.
resp (responsible party) indicates the individual responsible for identifying and measuring the space.
god if wommen had writen storyes As <space quantity="7" unit="char"/> han within her
oratoryes
<supplied reason="space" resp="#ETD" source="#Hg">preestes</supplied> han within
her oratoryes
11.5.2 LinesTEI: Lines¶
dear to me
declaring I would prosecute by law — hindered a man's proceedings who <hi rend="underline">had obtained all the letters to Mr Boyd</hi>
by law — hindered a man's proceedings who <hi xml:id="cstart1" rend="underline">had
obtained all the letters to Mr Boyd</hi>
<!-- ... -->
<certainty target="#cstart1" locus="start" degree="0.70">
<desc>may begin with previous word</desc>
</certainty>
Where the area of text marked overlaps other areas of text, for example crossing a structural division, one of the spanning mechanisms mentioned above must be used; for example where the line is thought to mark a deletion, the delSpan element may be used. Where it is desired simply to record the marking of a span of text in circumstances where it is not possible to surround the text with a hi element, the span element may be used with the rend or type attribute indicating the style of line-marking.
More work needs to be done on clarifying the treatment of other textual features marked by lines which might so overlap or nest. For example, in many Middle English manuscripts (e.g. the Jesus and Digby verse collections), marginal sidebars may indicate metrical structure: couplets may be linked in pairs, with the pairs themselves linked into stanzas. Or, marginal sidebars may indicate emphasis, or may point out a region of text on which there is some annotation: in many manuscripts of Chaucer's Wife of Bath's Prologue lines 655–8 are marked with nesting parentheses against which the scribe has written nota.
Such features could be captured by use of the note element, containing a prose description of the manuscript at this point, enhanced by a link to a visual representation (or facsimile) of the feature in question. For example, in the Chaucer example just cited, one may wish to record that the nota is written in the Hengwrt manuscript in the right margin against a single large left parenthesis bracketing the four lines, with two right parentheses in the right margin bracketing two overlapping pairs of lines: the first and third, the second and fourth. The note element allows us to record that the scribe wrote nota, but is not well-adapted to show that the nota points both at all four lines and at two pairs of lines within the four lines. The metamark element discussed in section 11.3.4.2 Metamarks above provides better facilities for this kind of complex annotation.
11.6 Headers, Footers, and Similar MatterTEI: Headers, Footers, and Similar Matter¶
Such information as page numbers, signatures, or catchwords may be recorded in a specialized fw element provided for that purpose. Although the name derives from the term forme work, used in description of early printed documents (the ‘forme’ being the block used to hold movable type), the fw element may be used for such features of any document, written or printed. Note that the purpose of this element is to record page numbers etc. actually present in the document being encoded, not necessarily to provide a complete or accurate pagination of it.
- fw (forme work) contains a running head (e.g. a header, footer), catchword, or similar material appearing on the current page.
- running heads (whether repeated or changing on every page, or alternating pages)
- running footers
- page numbers
- catch-words
- other material repeated from page to page, which falls outside the stream of the text
<fw type="pageNum" place="top-right">29</fw>
<fw type="sig" place="bot-centre">E3</fw>
<fw type="catch" place="bot-right">TEMPLE</fw>
11.7 ChangesTEI: Changes¶
- a system to assign phenomena to a particular change
- a way to characterize a change, in itself and in relation to other changes.
- listChange groups a number of change descriptions associated
with either the creation of a source text or the revision of an encoded text.
ordered indicates whether the ordering of its child change elements is to be considered significant or not - change gibt eine bestimmte Veränderung oder Korrektur an einer bestimmten Version eines elektronischen Textes an, an der verschiedene Bearbeiter beteiligt sind.
In the following example an editor has identified four distinct changes:
<creation>
<listChange ordered="true">
<change xml:id="ST-1">First stage, written in ink </change>
<change xml:id="ST-2">Second stage, with revisions written in the author's hand using pencil</change>
<change xml:id="ST-3">Fixation of the pencilled
revisions together with further revisions in the
author's hand using ink</change>
<change xml:id="ST-4">Additions in a different hand, probably at
a later stage</change>
</listChange>
</creation>
</profileDesc>
The listChange element carries an attribute ordered, which can take the
values true or false (the default). The attribute specifies
whether the order of child elements signifies a temporal order for the revision campaigns
which they document. In the example above, the editor has asserted that the four
stages distinguished are ordered chronologically according to the order of the
change elements. If necessary, listChange elements can be nested hierarchically. This may be
helpful in two cases. Firstly one can build up hypotheses about related revisions
step-by-step, starting with stages of smaller coverage, whose members are certainly
related, and then in a subsequent pass grouping these stages in turn, thereby extending
their reach.
<creation>
<listChange>
<change xml:id="o">An unrelated change note</change>
<listChange xml:id="m">
<change xml:id="m1">Alterations on one manuscript page, certainly
related</change>
<change xml:id="m2">Alterations on another manuscript page, certainly
related</change>
</listChange>
<change xml:id="p">Another unrelated change note</change>
</listChange>
</creation>
</profileDesc>
A nested listChange elements is also useful to indicate a partial ordering of revision campaigns.
<change xml:id="ST1">The first stage</change>
<listChange>
<!-- We have no information about the order of these changes, except that they both followed ST1 and prececeded STX -->
<change xml:id="ST-rev1">A revision of the first stage</change>
<change xml:id="ST-rev2">Another revision of the first stage</change>
</listChange>
<change xml:id="STX">The last stage</change>
</listChange>
In addition to the possibility of ordering text stages in relation to each other, change elements may carry a number of attributes from the att.datable class (period, when, notBefore, notAfter, from, and to) which allow each stage to be dated as exactly or inexactly as necessary, in the same way as is currently possible for the TEI date element.
<creation>
<date notAfter="1816-07-18"/>
<listChange ordered="true">
<change xml:id="mod1" when="1816-07-16">The first draft of
<title>Persuasion</title>, completed by the date
<date>July 16 1816</date> which is
written after the word <q>Finis</q> at <ref target="#pers-30">page
30</ref>.</change>
<change xml:id="mod2" notBefore="1816-07-16">After the <date>16th of July</date>
Austen starts revision of the two final chapters, by rewriting the end and
adding a new zone (<ref target="#transp-1">pages 32-35</ref>) to be inserted at
<ref target="#insertion-p1">page 19</ref>. This stage is documented by the
deletion of the date (<date>July 16 1816</date>) at <ref target="#pers-30">page
30</ref>, and the addition of more text and of a new date (<date>July 18.
1816</date>) at <ref target="#pers-31">page 31</ref>
</change>
<change notBefore="1816-07-18">Before publication, after <date>July 18th,
1816</date> chapters 10-11 were broken into three chapters, 10, 11, 12, as
witnessed by the print.</change>
</listChange>
</creation>
</profileDesc>
Each change element, apart from declaring a distinct change in the creation of the document, may also contain references to other annotations contained within the teiHeader or in the document (as shown in the previous example). Such references, along with the textual content, are purely documentary and do not affect the textual stage associated with any element thus referred to. The association of a textual component with a change is always made explicitly, either by using the target attribute on the change element to point to one or more elements, or by pointing from the element or elements concerned to the change element by means of their change attribute. If a change element is associated with some element, it is also associated with all of that element's children, unless otherwise indicated, for example by a new value for the change attribute.
<add change="#secondStage">house</add>
mouse.</line>
<del>house</del>
<add>mouse</add>
</mod>.</line>
Elements such as add and del and the like carry an implied semantics concerning the order in which events in the writing of a document was carried out: something which is deleted must have been written before it was deleted; something which is added must have been added at a later stage of the writing. Even when a combination of such elements is used, the chronology can usually be inferred (see further 11.3.3.2 Use of the gap, del, damage, unclear, and supplied Elements in Combination). Explicit indication of the stage to which some modification belongs is mostly useful in situations where all the alterations identified in a document are to be grouped, for example chronologically.
<creation>
<listChange ordered="true">
<change target="#zone_1 #subst_3">First stage, written in ink by a scribe</change>
<change
target="#zone_2 #mod_1 #line_1 #line_2 #subst_1 #subst_2 #subst_4 #delSpan_1">Revised by Goethe using pencil</change>
<change
target="#redo_1 #redo_2 #redo_3 #subst_1 #subst_2 #delSpan_1 #add_1">Fixation of the revised passages and further revisions by Goethe using
ink</change>
</listChange>
</creation>
</profileDesc>
<sourceDoc>
<surface>
<zone xml:id="zone_1">
<line xml:id="line_1">
<handShift new="#g_bl"/>
<retrace hand="#g_t" xml:id="redo_1">Nun</retrace>
</line>
<line>
<handShift new="#jo_t"/>Ihr wanſtige Schuften mit den Feuerbacken</line>
<line xml:id="line_2">
<handShift new="#g_bl"/>
<retrace hand="#g_t" xml:id="redo_2">feiſt</retrace>
</line>
<line>Ihr glüht ſo recht vom Höllen Schwefel ſatt.</line> [...] </zone>
</surface>
</sourceDoc>
<text>
<body>
<l n="11656">
<subst xml:id="subst_1">
<del>Ihr</del>
<add>Nun</add>
</subst> wanſtige Schuften mit den Feuerbacken</l>
<l n="11657">Ihr glüht ſo recht vom Höllen Schwefel <subst xml:id="subst_2">
<del>ſatt</del>
<add>feiſt</add>
</subst>.</l>
</body>
</text>
The documentary transcription stresses the writing process, while the textual transcription emphasizes textual alterations. In either case, the change of writing activity associated with a particular feature in the transcript is explicitly indicated. From the documentary perspective, by assigning particular modifications to a specific change, we describe the writing process, in that they specify which segment has been written when . From the textual perspective, the markup concentrates simply on the existence of textual alterations and makes no explicit claims about the order of writing.
11.8 Other Primary Source Features not Covered in these GuidelinesTEI: Other Primary Source Features not Covered in these Guidelines¶
We repeat the advice given at the beginning of this chapter, that these recommendations are not intended to meet every transcriptional circumstance ever likely to be faced by any scholar. They are intended rather as a base to enable encoding of the most common phenomena found in the course of scholarly transcription of primary source materials. These guidelines particularly do not address the encoding of physical description of textual witnesses: the materials of the carrier, the medium of the inscribing implement, the organisation of the carrier materials themselves (as quiring, collation, etc.), authorial instructions or scribal markup, etc., except insofaras these are involved in the broader question of manuscript description, as addressed by the msdescription module described in chapter 10 Manuscript Description.
11.9 Module for Transcription of Primary SourcesTEI: Module for Transcription of Primary Sources¶
- Modul transcr: Transcription of primary sources
- Definierte Elemente: addSpan am damage damageSpan delSpan ex facsimile fw handNotes handShift line listTranspose metamark mod redo restore retrace sourceDoc space subst substJoin supplied surface surfaceGrp surplus transpose undo zone
- Definierte Klassen: att.coordinated att.global.change att.global.facs